MySQL Cluster SQL节点负载均衡、读写分离验证-基于Amoeba
龙年完成的Amoeba环境初步搭建工作,蛇年开始进行读写分离和负载均衡的验证工作。先祝大家蛇年一切顺利。上回的工作我们只是完成Amoeba框架的引入,但是并不满足读写分离场景的要求,因为最基本的,SQL节点只有一个。
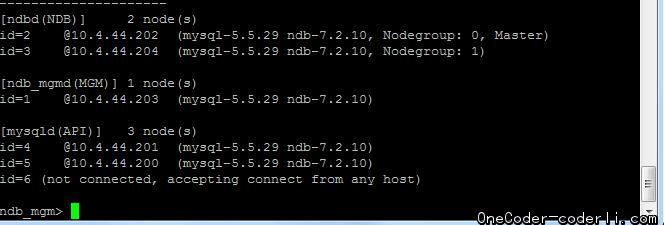
所以,我们首先需要添加一个SQL节点,具体操作不再赘述。添加,重启后,MySQL Clluster集群环境如下。
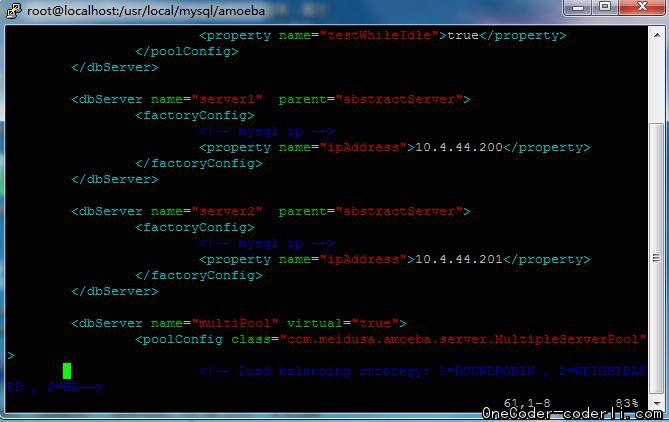
修改Amoeba的环境配置dbServers.xml,增加一个dbServer节点10.4.44.200。
重启Amoeba服务使配置生效。
此时,使用之前写好的JDBC代码直接访问Amoeba的服务即可完成对数据的操作,只需修改IP地址和端口(默认为8066)即可。
通过测试发现,通过访问Amoeba服务,确实完成对了SQL层的负载均衡,观察虚拟机的网络指标,发现两个SQL节点的网络负载比较平均。
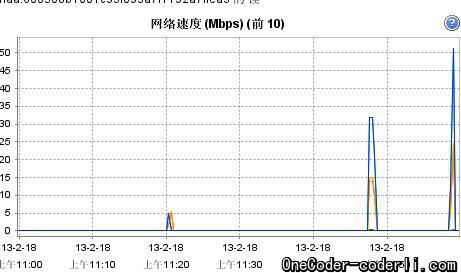
SQL200的网络负载
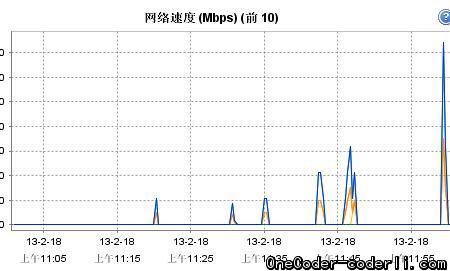
SQL201相同时刻的网络负载情况
读写分离配置。
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">server2</property>
<property name="writePool">server2</property>
<property name="readPool">multiPool</property>
<property name="needParse">true</property>
</queryRouter> 关键是打开默认注释掉的readPool和writePool 的配置项,这里可以配置单节点名称也可以填入在dbServers.xml中定义的虚拟节点的名称,比如这里的multiPool实际包含了server1,server2两个节点。Amoeba按照负载均衡策略进行读取。
注:上述配置是在不进行数据切分的情况下,快速进行读写分离的配置。
连接205的Amoeba节点进行读写操作,观察虚拟机监控图表,可以看到当读数据的时候,负载分担在server1和server2节点上,写数据的时候,只有server2有压力。
备注:Amoeba不能做什么
目前还不支持事务
暂时不支持存储过程(近期会支持)
不适合从amoeba导数据的场景或者对大数据量查询的query并不合适(比如一次请求返回10w以上甚至更多数据的场合)
暂时不支持分库分表,amoeba目前只做到分数据库实例,每个被切分的节点需要保持库表结构一致。
从第四点可以联想到,我们测试的环境是基于MySQL Cluster的多个SQL节点,底层的Data node自然是数据同步的,甚至都不存在他说的保持库表一致的问题。OneCoder也认为,Amoeba在设计之初的使用场景底层应该是基于独立的MySQL节点的。这也是OneCoder接下来考虑的验证工作:)