MySQL Cluster 使用小测小结(3)-数据节点添加和数据分配
继续OneCoder之前提出的要验证的问题,为了方便测试MySQL Cluster的数据分片功能,我们设置集群节点配置如下:
NoOfReplicas=1
DataMemory=50M
IndexMemory=10M
初始化重启节点:
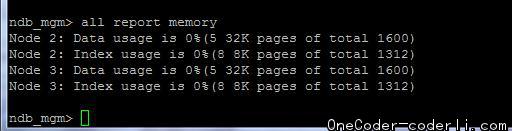
开始写入80w数据。观察写入过程,可以看到数据是大致均匀写入两个节点之中:
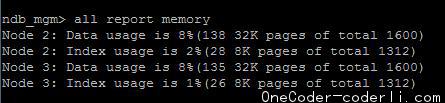
跟之前不同的事,这次不会双节点都保持完全 一样的内存占用了。这说明,这不是由于数据复制造成的,而是正常的数据分片导致。最终80w数据成功写入了容量均为50m的两个数据节点中。这说明MySQL Cluster是可以自动将数据分片保存的。
Begin to prepare statement.
It's up to batch count: 100000
Batch data commit finished. Time cost: 90128
It's up to batch count: 100000
Batch data commit finished. Time cost: 87141
It's up to batch count: 100000
Batch data commit finished. Time cost: 86353
It's up to batch count: 100000
Batch data commit finished. Time cost: 86775
It's up to batch count: 100000
Batch data commit finished. Time cost: 89635
It's up to batch count: 100000
Batch data commit finished. Time cost: 87782
It's up to batch count: 100000
Batch data commit finished. Time cost: 89180
It's up to batch count: 100000
Batch data commit finished. Time cost: 89021
All data insert finished. Total time cost: 706041

那么,如果是在集群已有存储容量不足的情况下,扩充新节点进来,会是怎样的情况呢。我们再测试一下。先去掉一个节点,将容量再调小。然后写入数据直到写满,再加入第二个节点,继续写入数据。看是否可以成功,并且观察数据的分配情况。
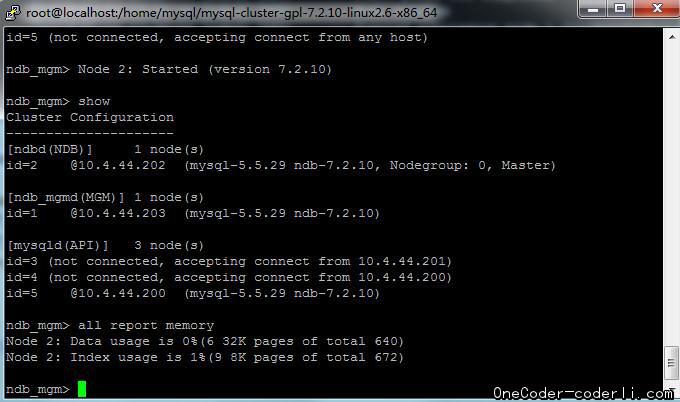
在写入的过程,也观察到另外一个现象,就是在一次批量写入没有提交的情况下,内存的占用大于存储需要的空间容量,在提交以后,这部分内存会释放,内存的占用量会降低。因此调整每批次写入的数据量,可在现有的空间中存入更多的数据。这里采用单批次1w输入写入。

注:在单批次20w的情况下。根本无法成功写入任何数据,10w的时候只能写入20w数据。
加入新节点:
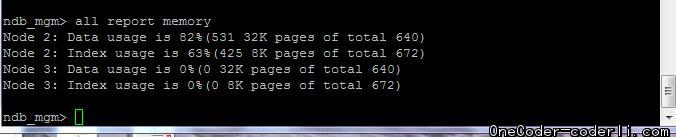
目前数据并没有自动调配。我们先继续写入数据测试,看看集群容量是否真的扩容了,并观察后续空间使用状况。数据库现有数据23w。直接继续写入数据,仍然提示空间不足。
观察到,新加入的节点是no nodegroup 状态。所以我们通过:
1
ndb_mgm>create nodegroup 3;
来创建nodegroup。然后再调整分区数据:
1
mysql> alter online table data_house reorganize partition;
发现分区果然有变化了。再次继续写入数据,成功!
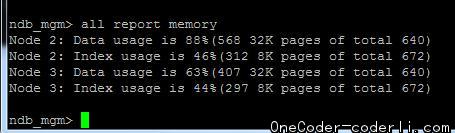
新加入的节点已经可以写入数据了。
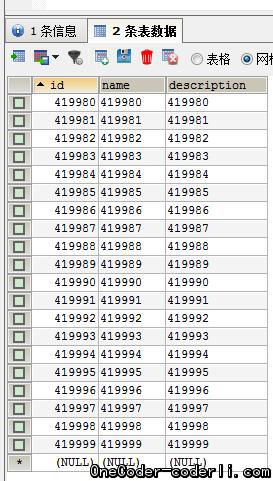
通过工具也可看到,数据库里已经有42w数据了。最终两个节点共写入50w数据。查询效率仍然是20ms左右。至此,MySQL Cluster的一些基本的功能特性,都验证完成了。不过想用于生产环境还需要更多的考量,目前网上也有很多改造过的开源和商业版本,如果有需要可以具体考察一下。