Python练习-常用内建模块base64
本部分学习Python中关于base64编码的基本操作。关于这部分内容,除了基本的base64操作外,我还查阅了一些资料,了解了base64的一些基础常识,比如:base64是因为什么出现的?编码规则等。我觉得了解了事务的背景,对于理解、掌握和应用该技术,是非常必要和有帮助的。
一、base64编码为什么出现
一个字节可表示的范围是 0 ~ 255(十六进制:0x00 ~ 0xFF), 其中 ASCII 值的范围为 0 ~ 127(十六进制:0x00 ~ 0x7F);而超过 ASCII 范围的 128~255(十六进制:0x80 ~ 0xFF)之间的值是不可见字符。
当不可见字符在网络上传输时,比如说从 A 计算机传到 B 计算机,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。为了解决这个问题,人们利用一种编码规则,将不可见字符变为可见字符,以确保数据在在网络上可靠传输。当然这个过程是可逆的,这就是base64编码的初衷。 Base64 的内容由 0 ~ 9,a ~ z,A ~ Z,+,/ 组成,正好 64 个字符,这些字符是在 ASCII 可表示的范围内,属于 95 个可见字符的一部分。
二、base64编码规则
前面介绍了,Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2⁶ = 64 ,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 base64 单元,即 3 个字节可由 4 个可打印字符来表示,也就是说经过base64编码后,数据体积膨胀了约33%。如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。 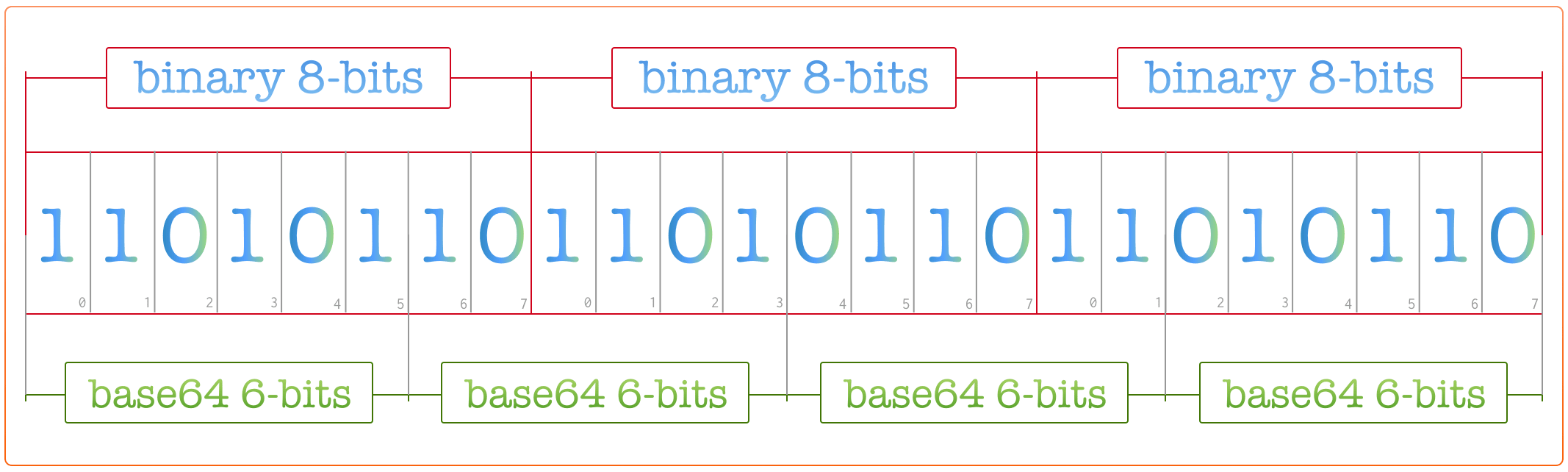 base64 常用于在处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML的一些复杂数据。也可以用来将图片进行编码,以文本方式进行传输,并还原。
base64 常用于在处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML的一些复杂数据。也可以用来将图片进行编码,以文本方式进行传输,并还原。
三、Python的base64编码操作
Python内置的base64可以直接进行base64的编解码
1
2
b_code = base64.b64encode(b'Man')
print(b_code)
输出:
b’TWFu’
可见原来3个字节的Man字符,编码后,变成了4个字节,TWFu
如果是b”Girl”四个字母的话,每个字母1个字节,8个bit可以表示。4 * 8 = 32,不能被6bit正除,需要补两个字节16个bit,变成48个bit,及转换后5个字符,两个=号,验证如下:
1
2
b_code = base64.b64encode(b'Girl')
print(b_code)
输出:
b’R2lybA==’
由于URL中不方便使用+和/,因此有一种URL safe的编码方式,即把+和/变成-和_
1
print(base64.b64encode(b'i\xb7\x1d\xfb\xef\xff'))
输出
b’abcd++//’
b’abcd–__’
由于=号也有可能在Cookie,URL中造成歧义,因此也有的base64编码将=号去掉。因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
最后做个小练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 练习 请写一个能处理去掉=的base64解码函数:
def safe_base64_decode(s):
l_s = len(s)
need_to_add_num = l_s % 4
result = None
if need_to_add_num == 0:
result = base64.b64decode(s)
else:
s = s + "=" * need_to_add_num
print(s)
result = base64.b64decode(s)
return result
# 测试:
assert b'abcd' == safe_base64_decode('YWJjZA==')
assert b'abcd' == safe_base64_decode('YWJjZA')
print('ok')
参考文献:
- https://en.wikipedia.org/wiki/Base64#Implementations_and_history
- https://cloud.tencent.com/developer/article/1583540
- https://www.liaoxuefeng.com/wiki/1016959663602400/1017684507717184